Next piece of evidence. Vestigial and other non-coding genetic characteristics.
Vestigial genetic sequences.
Looking at the nested hierarchy shown in the third image of post 4 in this series we can see humans and chimps (along with the rest of the primates) are grouped inside a larger group of animals. Their grouping also indicates a recent evolutionary divergence from that group. This is corroborated by the fossil record. Now… the members of this larger group of animals are capable of synthesizing ascorbic acid, also known as vitamin C. Humans and primates are not. As our little evolutionary branch of the tree only recently diverged from the rest of the group, and since large scale gene deletions are extremely rare (usually a gene is disable because of a disabling mutation… it is not completely removed from the DNA) if evolutionary theory is correct we should expect to still be able to find clear evidence of the genetic sequence responsible for the synthesis of ascorbic acid in humans and primates (even though we are not capable of such synthesis) and subsequently compare it to the functional sequence in other animals and determine what alteration made to it caused it to become non-functional. This is a prediction unique to evolution, relying entirely on the premise that we inherited our genetic material from an ancestral source we share in common with those other animals in the larger group.
This prediction was confirmed in the early 1990s with the identification of the L-gulano-gamma-lactone oxidase genetic code in humans and primates. Subsequent analysis showed it had experienced a frame shift mutation that had caused it to become non-coding.
Let me summarize this again to ensure it is fully understood.
1. Humans and primates do not produce their own ascorbic acid. From simple direct observation there is NO reason to think they would have the genetic code required to do so.
2. The nested hierarchical structure humans and primates fit into within an evolutionary framework however indicates that they diverged from a wider group at a time when ascorbic acid synthesis was already present in the genome of the group, and thus that genetic information should have been inherited.
3. Since we do not produce ascorbic acid, and since it would be unusual to have an entire gene simply deleted in entirety from the genome, evolutionary theory and evolutionary theory alone predicts we should find vestigial genetic code for the production of ascorbic acid which was inherited from an earlier common ancestor in the human and primate genomes… and which has since been deactivated by mutation.
4. They looked for it. They found it. Deactivated by a frame shift mutation that wiped out the end of the sequence on that gene. Prediction confirmed.
Once again… I can’t stop someone from looking at this clear example of evidence of common evolutionary descent and declaring “it just looks that way because it was designed that way” but at this point, whether it’s impossible to disprove that statement or not, it would be beginning to get silly… proposing that the same non functional section of genetic code would be designed into humans and primates… and in such a way that it looked just like a functional piece of code in other animals that had undergone a mutation. If you want to design an organism that doesn’t synthesize its own ascorbic acid you sure as heck don’t need to give it most of the genetic code to do so only to make it not do so!
And this is hardly the only example of a vestigial genetic sequence that fit this pattern…. Olfactory receptor genes, RT6 protein genes, etc… the genetic code of all kind of organisms is packed with pseudogenes that used to code for something in an ancestor… still codes for that same function in related organisms, but has been disabled in one particular group by a crippling mutation while the bulk of the genetic code remains present.
Continuing on that line, there is also the matter of endogenous retroviral insertions.
Endogenous Retroviral Insertions
Retroviruses contain viral RNA, as opposed to the DNA in humans and other animals and plants… and they also contain a reverse transcriptase. What this means is that they have the ability to insert the complimentary DNA sequence of their own RNA genetic code into the genetic code of the host organism they infect. It’s how they reproduce. Example of a retrovirus: HIV.
Here’s how it works in a little more detail.
The virus infects a cell. It then releases the reverse transcriptase. The reverse transcriptase makes a copy of viral DNA from the viral RNA. The viral DNA then gets spliced into the DNA of the infected host cell, at a random location… so from now on every time that cell’s DNA is replicated the viral DNA gets replicated right along with it. In the meantime the viral DNA in the cell serves as the template for producing new copies of viral RNA. Now, while the initial insertion point of the viral DNA is random, in any subsequent copies made when the cell reproduces the exact same location of the viral DNA will be copied as well.
(Side note: The random nature of the retroviral insertion is one well known hurdle faced by researchers of genetic therapies, since if they attempt to engineer a retrovirus to deliver their developed therapy to their patient a random insertion could place it in the middle of DNA that was already coding for something else that was fairly important)
When a retrovirus infects a host’s reproductive system - and thus the copies of the host’s DNA which will be passed on to it’s offspring - it becomes heritable by the host organism’s offspring, passed onto them just like any gene would be. And again, the location of the viral DNA within the genetic code will be the same as in the parent organism the DNA was inherited from.
The human genetic code is huge. It’s over 3 billion base pairs long. The genetic codes of the other primates (chimps, gorillas, orangutans, gibbons, etc…) are similarly massive. The odds of a single retrovirus infecting two of these individual species independently and just happening through pure coincidence to randomly splice themselves into the exact same location in their DNA are, obviously, not good.
So if we were to find, for example, that an analysis of human and chimp DNA revealed a single identical retroviral genetic sequence at an identical location that would be extremely solid evidence that they had both inherited that genetic sequence from a common ancestor who was originally infected by the retrovirus… thus also inheriting it’s common location in their genome. Not only is this a similar type of evidence that is possible from analysis of other genetic information… but this information in particular is completely immune to being hand-waved away as being somehow due to “common design” of similar appearing animals or functions as IDers and creationists attempt (and I stress “attempt”) to do with other findings. There is no rational way to argue that a viral infection was an element of the design of an organism.
So, in all of our studying of the genetic codes of humans, chimps, and other primates have we found a case of a retroviral insertion in an identical location in both humans and another primate? No…
We’ve found multiple cases.
The odds of finding a single example occurring by coincidence are mind bogglingly bad. The odds of finding multiple examples occurring by coincidence are exponentially worse. They defy description. And for the final nail in the coffin (as if we needed it), there’s the pattern we find these common insertions in:
So far (with the sequencing of the human and primate genomes still far from complete) the primate species we share the most common insertions with are chimps, which all other genetic evidence says are the most closely related primates to humans. We share the second most common insertions with gorillas… the second most closely related primates. Third and fourth most common insertions = orangutans and gibbons respectively… also the third and fourth most closely related according to the other genetic evidence. Fifth most = old world monkeys… sixth most = new world monkeys… fifth and sixth most closely related groups, respectively, according to the other genetic evidence.
A diagram of the pattern of insertions in question, courtesy of talk.origins ("Grant, do you just take all your evolution related imaged from talk.origins?" you ask. Pretty much. They're just that good. Go read the site when you're done here):
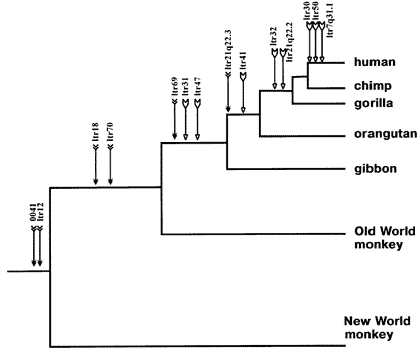
Again, it’s impossible to prevent a claim that this is the case “just because God made it that way”… but again, it’s getting silly when the alternative hypothesis to what has been presented is that God deliberately designed identical remnants of past genetic infections into different species in a nested hierarchical structure in just such a way that it would really really look like they evolved from common ancestry.

No comments:
Post a Comment